
Langchain-based RAG using MLflow for tracing and evaluation, with its LLM-as-judge infrastructure
If you've seen any of my other DS/ML (data science / machine learning) content you know I'm a big fan of MLflow. The bottom line is that making a new model is typically the quick and easy part. It's figuring out how to make it consistent and how to improve it that are the hard part -- and the key is being fastidious and objective about what you (and your team) know about the model and data that you're working with. This is equally as true with GenAI language models and RAG (retrieval augmented generation) as it is for classic machine learning and deep learning. MLflow 3 has an expansive feature set for GenAI development and quantifiable evaluation that provides a lot of the toolset straight out of the "box" (container?).
The code for this project is in my RAG_MLflow_Eval repo in GitHub; we'll evaluate question-answering (QA) behavior implemented with Langchain and MLflow, including both a retrieval-augmented generation (RAG) mode and a no-RAG baseline mode for performance comparison. The goal is to quantify how much the RAG component improves answer quality relative to the baseline LLM. To do so we'll use OpenAI's
The key run parameters to note that I've used for these results here are defaults in that repo, and for use with the dataset in this project there were 10 website URLs used to generate the document database.
MLflow UI layout/contents
After two runs, a RAG run and a no-RAG run, we'll find four entries in the "Training runs" section of MLflow, two each for the RAG and no-RAG runs. Why two each? The first assembles the RAG app and saves it as a reusable tool (which it saves and lists in the "Agents" section), using a specified set of document URLs for retrieval. The second is an initial baseline evaluation of that RAG app with a given reusable dataset of Q&A pairs to quantify the app's performance. Since the datasets and apps are reusable, there can be multiple evaluation runs for the same app with different datasets, or for the same dataset with different apps/agents. The RAG_MLflow_Eval script performs both app creation and baseline evaluation on every execution, producing two MLflow runs each time it is executed:
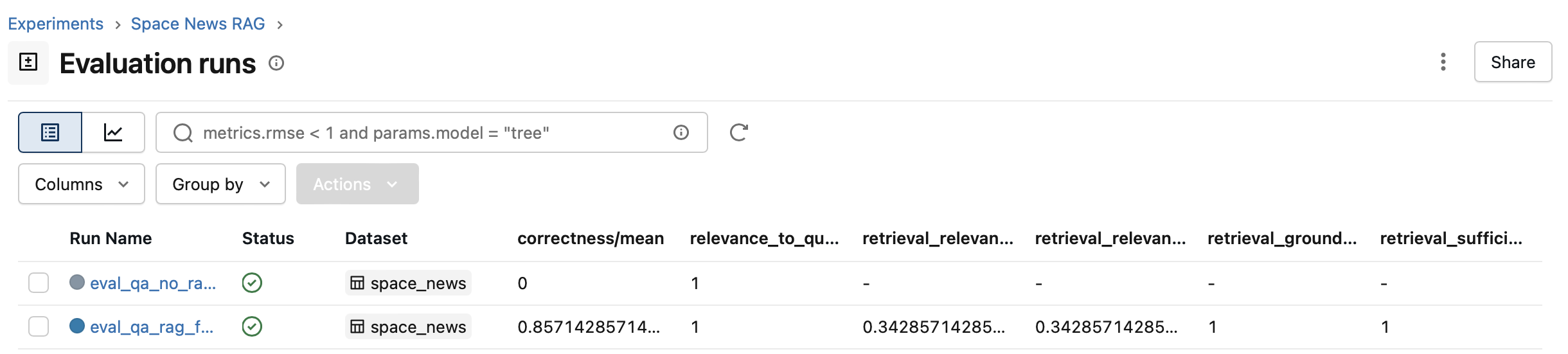
The evaluation runs, the second of each pair, can additionally be found in the "Evaluation runs" section, where additionally the performance metrics are tabulated for comparison (in addition to being accessible within each individual run). Note the no-RAG run does not have retrieval-related metrics since there was no retrieval done for that run. Notice that the correctness metric is substantially higher for the RAG run than for the no-RAG run; we'll come back to that shortly.
In my view MLflow gets a little loose with the terms "agent", "app", and "model", but that's ok, it functionally works that the RAG apps in question get logged here in the "Agent versions" section:
Similarly there's the "Datasets" section, where you can review and search the questions (inputs) and expected answers (expectations) used for the evaluations. (Note in these examples that all these refer to events in 2024 and beyond -- ie after the knowledge cutoff date of the LLM.)
Quantifying evaluation
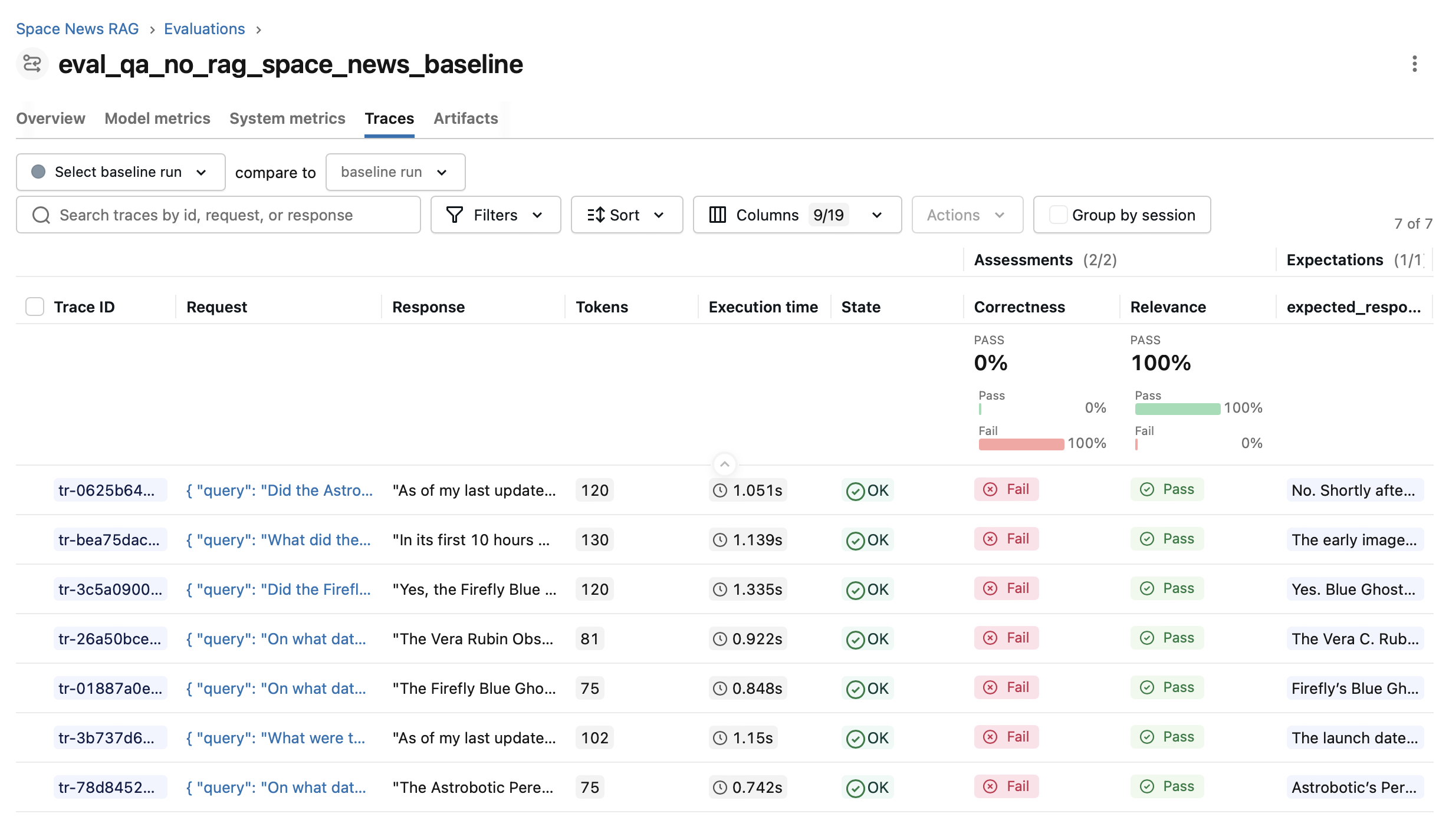
Without RAG the LLM hallucinates the answers to the evaluation questions that refer to events after its knowledge cutoff date, resulting in abysmal performance:
(click the image to cycle thru a few examples of the judge-LLM responses)
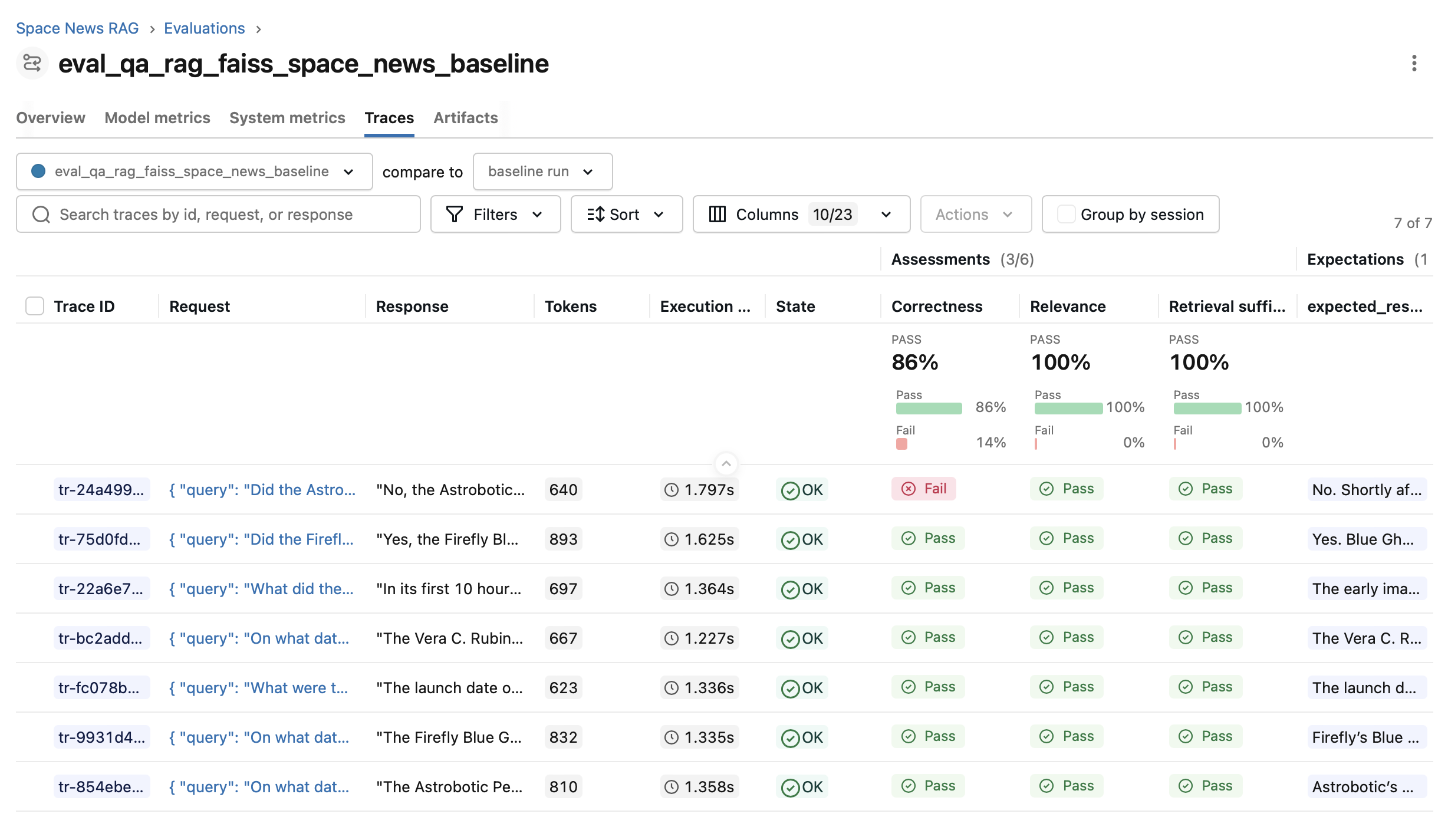
With RAG enabled the retrieved documents provide the correct information about events after its knowledge cutoff date, much improving the performance:
(click the image to toggle an example of the judge-LLM responses)
Performance metrics
So now let's talk about these performance metrics and how they're defined. Sorry their names get cut off in some of the above snapshots; here they are. Each is a mean across a set of per-eval-question binary scores generated by a judge LLM. It helps to consider these in terms of what gets compared among the input query, retrieved docs content, generated answer, and expected response (ground truth).
Just clarifying the retrieval_relevance/precision mean vs retrieval_relevance mean above: for each Q&A answer logged in MLflow, for which k documents were retrieved, there are k retrieval_relevance binary scores logged, and one precision score logged which is the mean of those k retrieval_relevance binary scores. If every answer has the same k then the mean of retrieval_relevance/precision over all answers will equal the mean of retrieval_relevance over all answers as it happens to do in this limited project. But that's not always the case -- you could have different k in different answers and then they won't be equal. In that case reporting both addresses the weighting in those means.
Anyhow, for example my RAG app above has these scores:

which I interpret in this way:
Retrieval layer -- looks like a classic “high recall, low precision” retrieval system:
To be validated via more MLflow evaluation runs of course.
If you've seen any of my other DS/ML (data science / machine learning) content you know I'm a big fan of MLflow. The bottom line is that making a new model is typically the quick and easy part. It's figuring out how to make it consistent and how to improve it that are the hard part -- and the key is being fastidious and objective about what you (and your team) know about the model and data that you're working with. This is equally as true with GenAI language models and RAG (retrieval augmented generation) as it is for classic machine learning and deep learning. MLflow 3 has an expansive feature set for GenAI development and quantifiable evaluation that provides a lot of the toolset straight out of the "box" (container?).
The code for this project is in my RAG_MLflow_Eval repo in GitHub; we'll evaluate question-answering (QA) behavior implemented with Langchain and MLflow, including both a retrieval-augmented generation (RAG) mode and a no-RAG baseline mode for performance comparison. The goal is to quantify how much the RAG component improves answer quality relative to the baseline LLM. To do so we'll use OpenAI's
gpt-4o-mini as the baseline LLM, which has a knowledge cutoff date in 2023. So asking it about events that have happened since that date is likely to produce incorrect or hallucinated answers. Then we'll supply a set of more recent documents (webpages in this case) supplying accurate information about those events, and have the RAG process inject the relevant bits into the LLM prompt to provide it the correct information. And as you'd expect, in comparing the two cases we'll see a significant difference in performance. Please see the GitHub repo for details in installing and running the code -- it's broken into distinct Python modules with expansion in mind (rather than in say a Jupyter notebook), easily packaged for use elsewhere. Here we'll just look at the results in MLflow after the runs are done.The key run parameters to note that I've used for these results here are defaults in that repo, and for use with the dataset in this project there were 10 website URLs used to generate the document database.
params = {
"mode": "rag", # "rag" or "no_rag"
"retrieval_backend": "faiss", # (for now the only choice)
"chunk_size": 500,
"chunk_overlap": 50,
"retrieval_top_k": 5,
"embedding_model": "text-embedding-3-small", # langchain default is "text-embedding-ada-002"
"base_llm": "gpt-4o-mini", # the arbitrary model the RAG is built around
"judge_llm": "openai:/gpt-4o-mini", # mlflow default, note "openai:/" is required
}
MLflow UI layout/contents
After two runs, a RAG run and a no-RAG run, we'll find four entries in the "Training runs" section of MLflow, two each for the RAG and no-RAG runs. Why two each? The first assembles the RAG app and saves it as a reusable tool (which it saves and lists in the "Agents" section), using a specified set of document URLs for retrieval. The second is an initial baseline evaluation of that RAG app with a given reusable dataset of Q&A pairs to quantify the app's performance. Since the datasets and apps are reusable, there can be multiple evaluation runs for the same app with different datasets, or for the same dataset with different apps/agents. The RAG_MLflow_Eval script performs both app creation and baseline evaluation on every execution, producing two MLflow runs each time it is executed:
The evaluation runs, the second of each pair, can additionally be found in the "Evaluation runs" section, where additionally the performance metrics are tabulated for comparison (in addition to being accessible within each individual run). Note the no-RAG run does not have retrieval-related metrics since there was no retrieval done for that run. Notice that the correctness metric is substantially higher for the RAG run than for the no-RAG run; we'll come back to that shortly.
In my view MLflow gets a little loose with the terms "agent", "app", and "model", but that's ok, it functionally works that the RAG apps in question get logged here in the "Agent versions" section:
Similarly there's the "Datasets" section, where you can review and search the questions (inputs) and expected answers (expectations) used for the evaluations. (Note in these examples that all these refer to events in 2024 and beyond -- ie after the knowledge cutoff date of the LLM.)
Quantifying evaluation
Without RAG the LLM hallucinates the answers to the evaluation questions that refer to events after its knowledge cutoff date, resulting in abysmal performance:
(click the image to cycle thru a few examples of the judge-LLM responses)
With RAG enabled the retrieved documents provide the correct information about events after its knowledge cutoff date, much improving the performance:
(click the image to toggle an example of the judge-LLM responses)
Performance metrics
So now let's talk about these performance metrics and how they're defined. Sorry their names get cut off in some of the above snapshots; here they are. Each is a mean across a set of per-eval-question binary scores generated by a judge LLM. It helps to consider these in terms of what gets compared among the input query, retrieved docs content, generated answer, and expected response (ground truth).
- correctness mean: Measures how well the generated answer matches the expected response in terms of factual/semantic correctness.
- relevance_to_query mean: Measures how well the generated answer addresses the input query, regardless of whether it exactly matches the reference answer.
- retrieval_relevance/precision mean: Measures the mean fraction of retrieved docs content that is relevant to the input query (i.e. mean of the per-answer retrieval "precision" entries).
- retrieval_relevance mean: Measures the average relevance of retrieved docs content to the input query (i.e. mean of per-retrieved-doc binary relevances per-answer, over all answers).
- retrieval_groundedness mean: Measures whether the generated answer is supported by the retrieved docs content.
- retrieval_sufficiency mean: Measures whether the retrieved docs content contains enough information to fully and accurately answer the input query.
Just clarifying the retrieval_relevance/precision mean vs retrieval_relevance mean above: for each Q&A answer logged in MLflow, for which k documents were retrieved, there are k retrieval_relevance binary scores logged, and one precision score logged which is the mean of those k retrieval_relevance binary scores. If every answer has the same k then the mean of retrieval_relevance/precision over all answers will equal the mean of retrieval_relevance over all answers as it happens to do in this limited project. But that's not always the case -- you could have different k in different answers and then they won't be equal. In that case reporting both addresses the weighting in those means.
Anyhow, for example my RAG app above has these scores:
which I interpret in this way:
Retrieval layer -- looks like a classic “high recall, low precision” retrieval system:
- High retrieval_sufficiency (1.0): we retrieve enough information
- High retrieval_groundedness (1.0): generated answers are strongly supported by retrieved content.
- Low retrieval precision (0.342): we retrieve a lot of irrelevant noise (I see this when browsing doc chunks in MLflow; among good ones there are also chunks in other languages, chunks from bibliographic references, etc...)
- High relevance_to_query (1.0): answers stay on-topic
- Good correctness (0.857): answers are mostly accurate
To be validated via more MLflow evaluation runs of course.