
Semantic SQL experimentation with PostgreSQL's pgvector extension
For some types of semantic analysis we don't always need to always pull big dataframes of data out of the database to do the analysis externally if we already have embedding vectors stored in the database. PostgreSQL's pgvector extension provides powerful functionality for semantic search and aggregation right there in the SQL queries. Let's experiment with some of this by grabbing an arbitrary dataset (how about Kaggle's Seattle AirBnB listings/reviews dataset), popping that into a database, running an embedding model on that to create embedding vectors, and trying a number of SQL queries using this functionality. My semantic_sql_examples repo in GitHub does this; here's a walkthrough of the results.
As shown in the repo, this is the schema of the database populated with the dataset: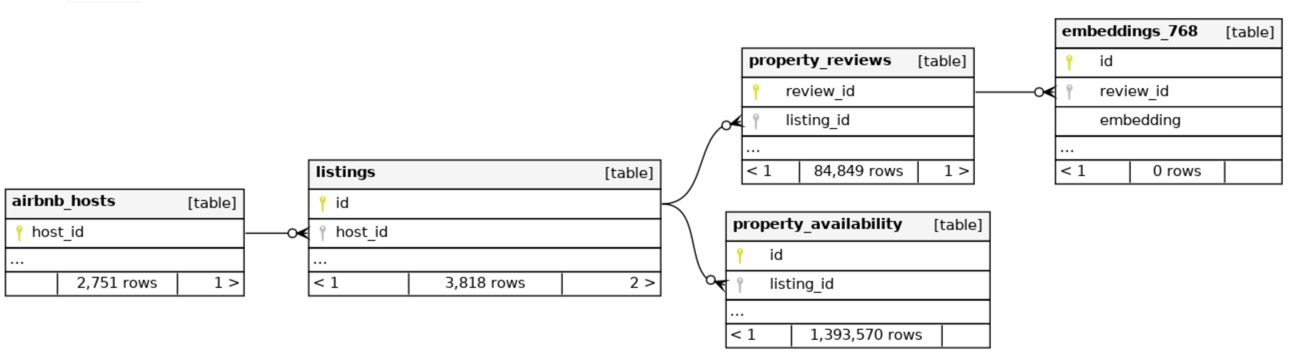
One big advantage of doing these types of semantic queries fully within the database is that the query can additionally include filtering on other relationships (e.g. only listings in a certain neighborhood, under a certain rate, or for a certain host) on top of the similarity/proximity calculations, potentially making an enormous difference in the amount of data pulled and the efficiency of the overall run. But for now we mainly focus on the review comments in property_reviews and the embedding vectors and tags in embeddings_768 (ie 768-dimensional embeddings were used here, generated by either the ViT-L-14 model from OpenCLIP or the Sentence Transformers E5-base-v2 model from HuggingFace, per configuration setting).
A key enabling line in a PostgreSQL database is:
So if we have a column
We could also use a line like
While all the above is about operations done strictly within the database via the SQL, I couldn't resist playing with some simple clustering on these embedding vectors, so additionally I ran that externally and saved the cluster-number result into tags in the embeddings_768 table to explore the results via SQL queries. (See the repo for details of how the clustering was done.)
Here then are a few examples of results generated for this Kaggle Seattle AirBnB reviews dataset; the semantic_sql_examples repo has the steps to populate the database and create the embedding vectors and so on, in addition to these example queries.
Reviews whose embeddings are 5-closest and 5-farthest from a source comment
For example, in this run the negative "host cancelled" theme of the source comment was found in the closest comments, and contrasted glowing compliments in the farthest comments. This query centers around the
Projecting review comments onto "semantic axes" such as "clean" vs "dirty"
For example, in this run the semantic axis "clean" vs "dirty" appeared to work pretty accurately, but to do so required using the seed poles which were the whole-sentence versions of "clean" and "dirty" rather than single words version (ie abssemaxis=18 rather than abssemaxis=8 in compute_semaxis_embeddings.py). The comment_len field (comment length ie number of characters) helped in analyzing the patterns in short/single-word seed poles associating with short/single-word comments regardless of comment topic (not shown here). This query centers around the (e.embedding <#> a.axis_embedding) form mentioned above.
Inspecting comments grouped into clusters that were generated by cluster.py
Yes, this example did require extracting data from the database, running the clustering externally, and inserting results (cluster numbers per comment) back into the database, but certainly easy enough to do when you have a pile of embedding vectors already there in the database. For example, in this run Cluster 40 appeared to be about cabins. The details of the clustering itself are in the repo, but overall since most of that work is done outside the database, the query in this case is much smaller than the others.
Also acknowledging that these types of results are sensitive to the model used to generate the embeddings, the parameters used in modeling (such as the number-of-dimensions in the PCA and UMAP steps in the clustering), and the form of the semantic axis seed words/phrases relative to the model choice. Of course such details are where the real work is in practice. But these types of semantic SQL operations can be supremely enabling -- in many situations it sure beats the heck out of trying to endlessly expand some complex regexp expressions.
Lastly, it turns out LangChain now has an integration package called
For some types of semantic analysis we don't always need to always pull big dataframes of data out of the database to do the analysis externally if we already have embedding vectors stored in the database. PostgreSQL's pgvector extension provides powerful functionality for semantic search and aggregation right there in the SQL queries. Let's experiment with some of this by grabbing an arbitrary dataset (how about Kaggle's Seattle AirBnB listings/reviews dataset), popping that into a database, running an embedding model on that to create embedding vectors, and trying a number of SQL queries using this functionality. My semantic_sql_examples repo in GitHub does this; here's a walkthrough of the results.
As shown in the repo, this is the schema of the database populated with the dataset:
One big advantage of doing these types of semantic queries fully within the database is that the query can additionally include filtering on other relationships (e.g. only listings in a certain neighborhood, under a certain rate, or for a certain host) on top of the similarity/proximity calculations, potentially making an enormous difference in the amount of data pulled and the efficiency of the overall run. But for now we mainly focus on the review comments in property_reviews and the embedding vectors and tags in embeddings_768 (ie 768-dimensional embeddings were used here, generated by either the ViT-L-14 model from OpenCLIP or the Sentence Transformers E5-base-v2 model from HuggingFace, per configuration setting).
A key enabling line in a PostgreSQL database is:
CREATE EXTENSION IF NOT EXISTS vectorwhich installs the pgvector extension. If we then have a column with the
vector(N) datatype (in my case N=768), we can then use new operators like cosine distance (<=>), inner product (<#>), L2 distance (<->), and L1 distance (<+>).So if we have a column
embedding of type vector(768) in the embeddings_768 table, we can do something like this to order the other comments by their cosine distance to the comment in id = 98295, truncating to get the top 5 closest comments:(By the way, just clarifying that while here I showed the query in terms of "cosine distance", in the repo and results at bottom they happened to be outputted instead as "cosine similarity" = 1 - "cosine distance"; both forms are common.)
SELECT
e2.id AS embed_id,
pr.review_id AS review_id,
pr.comments,
(e1.embedding <=> e2.embedding) AS distance
FROM config
JOIN embeddings_768 e1 ON e1.id = 98295
JOIN embeddings_768 e2 ON e1.id <> e2.id
JOIN property_reviews pr ON pr.review_id = e2.review_id
ORDER BY distance ASC
LIMIT 5
We could also use a line like
(e.embedding <#> a.axis_embedding) to compute the dot product, which can be interpreted as the degree of alignment of the embedding with the semantic axis. The semantic axis a.axis_embedding is generated by differencing the vectors of two polar-opposite terms (e.g. "clean" and "dirty") to create an axis along which embedding vectors can be compared in a more restricted topical sense.While all the above is about operations done strictly within the database via the SQL, I couldn't resist playing with some simple clustering on these embedding vectors, so additionally I ran that externally and saved the cluster-number result into tags in the embeddings_768 table to explore the results via SQL queries. (See the repo for details of how the clustering was done.)
Here then are a few examples of results generated for this Kaggle Seattle AirBnB reviews dataset; the semantic_sql_examples repo has the steps to populate the database and create the embedding vectors and so on, in addition to these example queries.
Reviews whose embeddings are 5-closest and 5-farthest from a source comment
For example, in this run the negative "host cancelled" theme of the source comment was found in the closest comments, and contrasted glowing compliments in the farthest comments. This query centers around the
(e1.embedding <=> e2.embedding) form mentioned above.\i example_queries/top5_closest_farthest.sql -- with src.eid = 98297┌──────────────────────────────────────────────────────────────────────────────────┬────────────┬───────┬────────────────┬───────────────┐
│ comment │ similarity │ count │ last_review_id │ last_embed_id │
├──────────────────────────────────────────────────────────────────────────────────┼────────────┼───────┼────────────────┼───────────────┤
│ The host canceled this reservation 13 days before arrival. This is an automated │ 1.000 │ 1 │ 58458460 │ 98297 │
│ --- │ │ │ │ │
│ The host canceled this reservation [X] days before arrival. This is an automated │ 1.000 │ 362 │ 58612186 │ 98328 │
│ The host canceled this reservation the day before arrival. This is an automated │ 0.957 │ 57 │ 58256584 │ 98218 │
│ The reservation was canceled [X] days before arrival. This is an automated posti │ 0.916 │ 396 │ 31614258 │ 54994 │
│ The reservation was canceled the day before arrival. This is an automated postin │ 0.875 │ 56 │ 31688399 │ 55087 │
│ The host canceled my reservation [X] days before arrival. │ 0.852 │ 18 │ 769194 │ 14864 │
│ ... │ │ │ │ │
│ Shawn's wonderful place in the Fremont neighborhood delighted us from the moment │ 0.097 │ 1 │ 26832019 │ 48546 │
│ Amanda's place in Ballard was exactly as described—lovely, quiet, and peaceful. │ 0.115 │ 1 │ 28857701 │ 51580 │
│ Elena's attention to detail was impeccable! Charcoal for the grill️ toiletries️ │ 0.117 │ 1 │ 43388601 │ 75138 │
│ Es war ein sehr nettes Erlebnis. Das Häuschen im Garten war charmant. Es tat gut │ 0.138 │ 1 │ 18001967 │ 35868 │
│ Lacy og Kyle gav os en dejlig velkomst ved at tage sig god tid til at vise os le │ 0.143 │ 1 │ 39198926 │ 67850 │
└──────────────────────────────────────────────────────────────────────────────────┴────────────┴───────┴────────────────┴───────────────┘
Projecting review comments onto "semantic axes" such as "clean" vs "dirty"
For example, in this run the semantic axis "clean" vs "dirty" appeared to work pretty accurately, but to do so required using the seed poles which were the whole-sentence versions of "clean" and "dirty" rather than single words version (ie abssemaxis=18 rather than abssemaxis=8 in compute_semaxis_embeddings.py). The comment_len field (comment length ie number of characters) helped in analyzing the patterns in short/single-word seed poles associating with short/single-word comments regardless of comment topic (not shown here). This query centers around the (e.embedding <#> a.axis_embedding) form mentioned above.
\i example_queries/sem_axis_query.sql -- with abssemaxis = 18 (clean/dirty sentences)┌─────────────┬────────────────────────────────────────────────────────────────────────────────────────────┬───────┬────────────┬───────┬────────────────┬───────────────┐
│ comment_len │ comment │ etype │ axis_value │ count │ last_review_id │ last_embed_id │
├─────────────┼────────────────────────────────────────────────────────────────────────────────────────────┼───────┼────────────┼───────┼────────────────┼───────────────┤
│ 149 │ Beautiful home with clean lines and safety options. It was exactly as pictured and would c │ CLIP │ 0.2050 │ 1 │ 40588992 │ 70351 │
│ 49 │ Great and very clean space in a perfect location! │ CLIP │ 0.2019 │ 1 │ 14542067 │ 30769 │
│ 68 │ Clean and attractive space, sweet neighborhood and responsive hosts. │ CLIP │ 0.1983 │ 1 │ 26420922 │ 47971 │
│ 73 │ A great and very efficient space that's private and very well maintained. │ CLIP │ 0.1926 │ 1 │ 16106530 │ 32927 │
│ 190 │ A beautiful modern townhouse that lives up to its reviews. Very clean, great light, awesom │ CLIP │ 0.1908 │ 1 │ 12156487 │ 28109 │
│ 79 │ Bright, clean, quiet space. Perfect location, exactly what we were looking for. │ CLIP │ 0.1884 │ 1 │ 33041863 │ 56991 │
│ 113 │ Very clean and simple. Fit our needs perfectly. Much better than a hotel room and in a coo │ CLIP │ 0.1879 │ 1 │ 50696063 │ 87825 │
│ 41 │ The space was clean, clear and beautiful. │ CLIP │ 0.1852 │ 1 │ 30009628 │ 53003 │
│ 124 │ Perfectly comfortable with every amenity we needed. The space was clean, and cozy and just │ CLIP │ 0.1831 │ 1 │ 27864817 │ 49804 │
│ 42 │ Very comfortable, clean and inviting home! │ CLIP │ 0.1828 │ 1 │ 44254036 │ 76569 │
│ │ ... │ ... │ │ │ │ │
│ 119 │ The house was dirty every where when we arrived. The owner promised let me get a refund, b │ CLIP │ -0.1583 │ 1 │ 48484980 │ 84120 │
│ 146 │ We are really dissapointed. The bathroom was very dirty. The house smelt not well. The hal │ CLIP │ -0.1471 │ 1 │ 50785364 │ 87971 │
│ 124 │ The bathroom was dirty and the pillows and sleeping bags that were provided were also dirt │ CLIP │ -0.1301 │ 1 │ 27508907 │ 49339 │
│ 974 │ We arrived to a very dirty house, all of the trash that was left from the previous renters │ CLIP │ -0.1252 │ 1 │ 30927806 │ 54284 │
│ 2493 │ The most amazing view and a fantastic location from which to see and experience the city. │ CLIP │ -0.1231 │ 1 │ 54969102 │ 94184 │
│ 869 │ Location is directly below major freeway #5. No air conditioning, and suite was 86 degrees │ CLIP │ -0.1199 │ 1 │ 40931176 │ 70917 │
│ 124 │ Grt location, but the house needs some TLC! Carpet was dirty, sinks slow, walls need paint │ CLIP │ -0.1188 │ 1 │ 51734909 │ 89536 │
│ 505 │ I'm sorry to say that our stay was less than desirable. The house, albeit old, was in a so │ CLIP │ -0.1136 │ 1 │ 18006701 │ 35878 │
│ 199 │ This is not a nice house to stay in. It’s old. A lot of the furniture is damaged and it sm │ CLIP │ -0.1110 │ 1 │ 34800475 │ 59937 │
│ 2106 │ While the location of this place is great, we had lots of difficulties with the hostess. I │ CLIP │ -0.1102 │ 1 │ 32507141 │ 56219 │
└─────────────┴────────────────────────────────────────────────────────────────────────────────────────────┴───────┴────────────┴───────┴────────────────┴───────────────┘
Inspecting comments grouped into clusters that were generated by cluster.py
Yes, this example did require extracting data from the database, running the clustering externally, and inserting results (cluster numbers per comment) back into the database, but certainly easy enough to do when you have a pile of embedding vectors already there in the database. For example, in this run Cluster 40 appeared to be about cabins. The details of the clustering itself are in the repo, but overall since most of that work is done outside the database, the query in this case is much smaller than the others.
\i example_queries/get_cluster.sql -- with cluster_num = 40┌──────────┬───────────┬───────────────────────────────────────────────────────────────────────────────────────────────┬───────────────────────────────────────┐
│ embed_id │ review_id │ comments │ tag │
├──────────┼───────────┼───────────────────────────────────────────────────────────────────────────────────────────────┼───────────────────────────────────────┤
│ 19865 │ 4932177 │ As always my eight year old daughter loved staying at the cabin, fishing, canoeing, captur... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 21222 │ 5964382 │ Our only regret is that we couldn't stay longer!! This cabin is beyond charming and the ba... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 21995 │ 6528575 │ Roberta & Dan are great! Their cabin was wonderful! Amazing woodwork and beautiful stone..... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 23071 │ 7336446 │ Gillian's Sky Cabin is a dream. We loved everything from the location to the amenities. If... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 23663 │ 7909018 │ I LOVED this place. Super clean, toasty warm (thanks to the roaring fire that was already ... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 24388 │ 8625191 │ I wanted to take a retreat from work and instead of driving a long distance or flying some... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 25043 │ 9292159 │ The cabin was fantastic. So quaint with the wood burning fireplace and the beautiful view.... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 26003 │ 10265299 │ Wow! This is like a cottage out of a fairy tale. Completely private, among tall trees with... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 26171 │ 10416488 │ I had really high expectations of this place, having seen the pictures on the airbnb listi... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 28825 │ 12964805 │ Talk about the fabulous life of Susanna and Ricki! The fiber glass lamps, velvet couch, th... │ {"cluster": 40, "embed_type": "CLIP"} │
│ 35416 │ 17669832 │ Roberta and Dans cabin was the last stop of our america-trip and we couldn't have chosen b... │ {"cluster": 40, "embed_type": "CLIP"} │
│ ... │ ... │ ...etc... │ ... │
Also acknowledging that these types of results are sensitive to the model used to generate the embeddings, the parameters used in modeling (such as the number-of-dimensions in the PCA and UMAP steps in the clustering), and the form of the semantic axis seed words/phrases relative to the model choice. Of course such details are where the real work is in practice. But these types of semantic SQL operations can be supremely enabling -- in many situations it sure beats the heck out of trying to endlessly expand some complex regexp expressions.
Lastly, it turns out LangChain now has an integration package called
langchain-postgres, which allows to implement a RAG vector store via PostgreSQL's pgvector as one more alternative to FAISS and others. Haven't actually tried it myself, but if already using PostgreSQL for other purposes at the same time, the thought of putting the vector store in there is appealing. We'll see.